Project
Candidate Ranking system
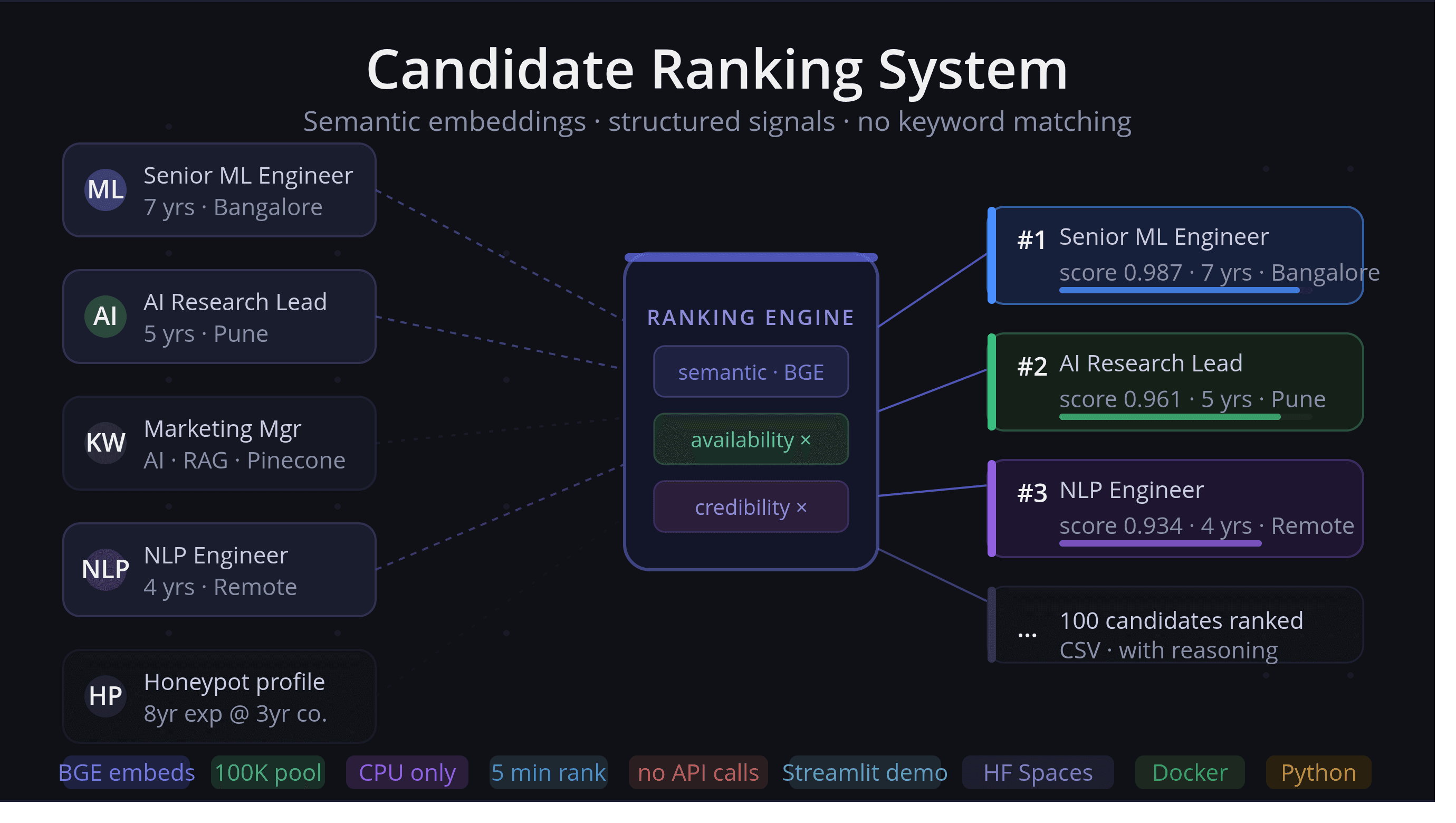
AI-powered candidate ranking system that combines semantic embeddings and structured signals to surface the best-fit candidates from a 100K pool - without keyword matching.
Problem
- Traditional recruiting tools rank by keyword overlap, rewarding profile stuffing over genuine fit.
- This system reads career narratives for meaning instead of matching tags.
- It weighs behavioral signals like availability and engagement, and penalizes implausible profiles.
- Built for the Redrob Data & AI Challenge, it ranks a 100K pool against a job description in under 5 minutes on CPU — no GPU, no external APIs.
Approach
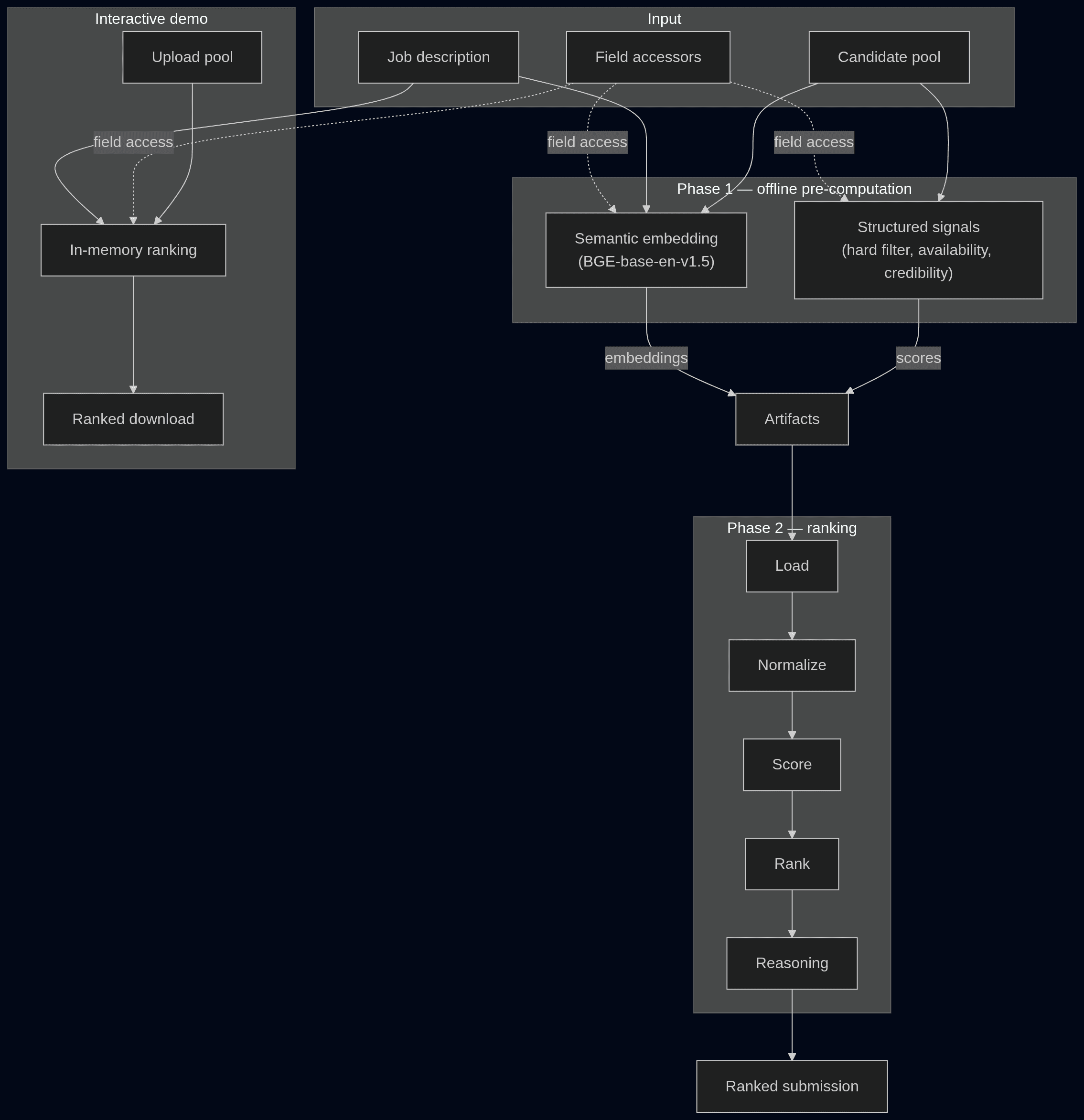
Two-phase architecture: precompute once, rank many
- Phase 1 does the heavy, query-independent work: structured scores plus the BGE embedding of every candidate.
- Phase 1 writes six parallel artifacts to
artifacts/:candidate_ids.npy,semantic_scores.npy, three Track-1 score arrays, andtrack1_details.pkl. - Phase 2 (phase2/rank.py) loads those artifacts and ranks with no model load, no network, and no GPU.
- The expensive embedding pass is paid once per population; re-ranking is pure NumPy.
- The demo (demo_pipeline.py) collapses both phases into one in-memory pass since uploaded pools have no precomputed artifacts.
Candidate text representation (Track 2)
- build_candidate_text serializes each candidate as: current role → career history → summary → skills → education.
- Career history is recency-weighted via
CAREER_TOKEN_BUDGET: 125 tokens for the most recent job, then 94, 62, and title-and-company-only for the 4th+ role. - Skills trail the narrative as a subordinate, noisy signal, and
beginnerproficiency is dropped (_PROFICIENCY_RANKkeeps only intermediate/advanced/expert). - Certifications are excluded as low-signal.
- Both candidate and JD text get BGE instruction prefixes for asymmetric retrieval.
Embedding model
- The model is
BAAI/bge-base-en-v1.5, a bi-encoder. - Each candidate and the JD (build_jd_text) are encoded independently.
- Semantic score is cosine similarity of L2-normalized vectors, a dot product once normalized (cosine_similarity_matrix).
- The bi-encoder lets candidate vectors be precomputed and reused across queries, matching the two-phase split.
Structured signals as multipliers (Track 1)
- All three scores are in
[0, 1]and read fields only through thefield_map.pyaccessor layer. - Hard filter (track1_hard_filter.py) is the product
location × yoe × work_mode × consulting_penalty × tenure. - Hard filter scores Pune/Noida 1.0, other tier-1 cities 0.9, the JD's 5–9 YOE band 1.0 (0.85 outer band), all-consulting careers (TCS/Infosys/Wipro/etc.) 0.3, and sub-12-month average tenure 0.50.
- Availability (track1_availability.py) is a weighted average:
open_to_work(0.30),last_active(0.25),response_time(0.20),notice_period(0.15), recruiter-response (0.05), applications-30d (0.05). - Availability excludes
interview_completion_rateas a weak discriminator. - Credibility (track1_credibility.py) weights profile completeness (0.25), log-scaled endorsements (0.20), education tier (0.20), GitHub (0.20), LinkedIn (0.10), verified contact (0.05).
- A
-1GitHub sentinel maps to 0.0, distinguishing "no account" from "low activity."
Final score and ranking
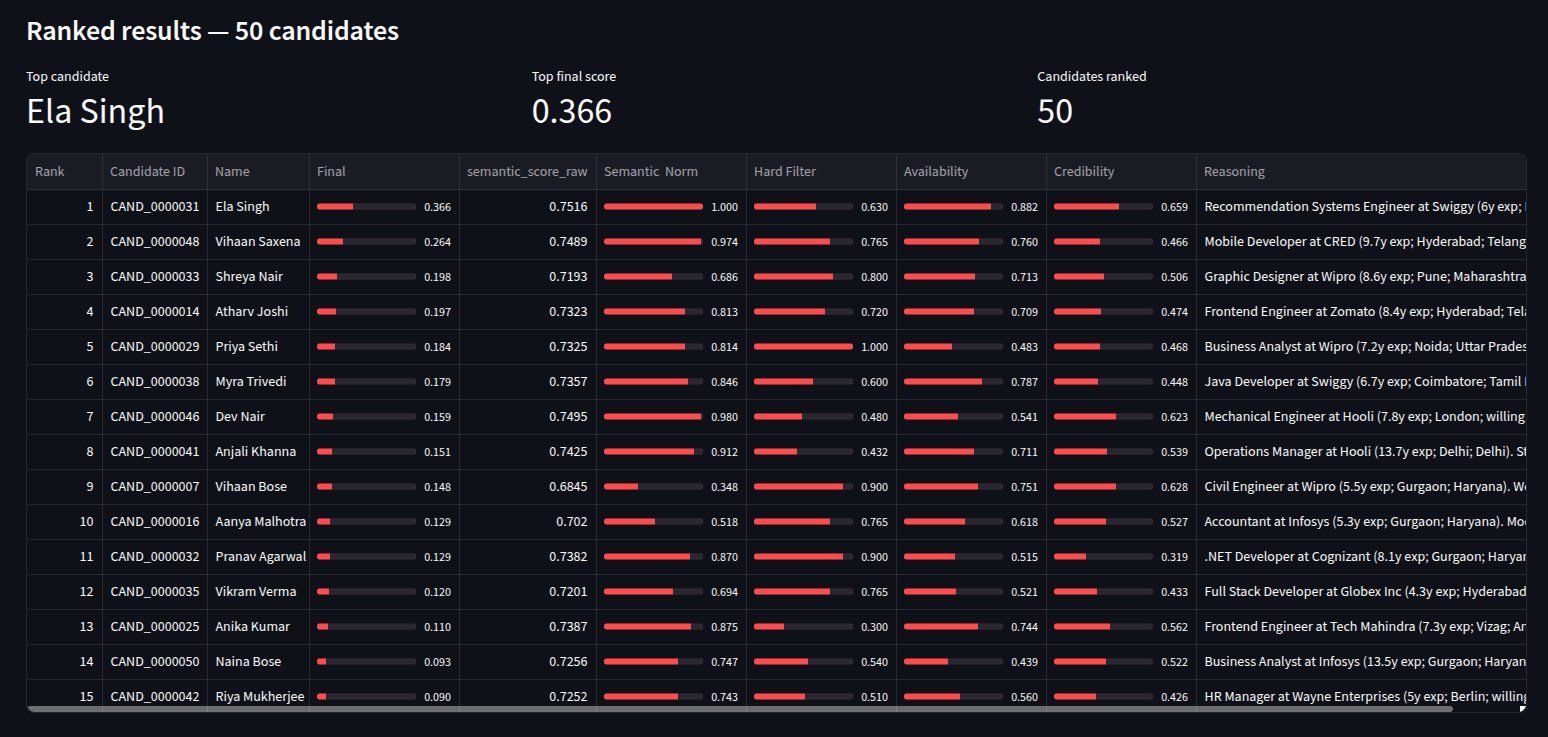
- Phase 2 min-max normalizes semantic scores across the population (normalize_semantic).
final_score = semantic_norm × hard_filter × availability × credibility.- The multiplicative form lets any single disqualifying signal (e.g. consulting-only career → 0.3) collapse the whole score.
- rank_top_n stable-sorts via
np.lexsorton(final, semantic_norm, hard_filter)descending and slices the top 100.
Reasoning generation
- build_reasoning emits a per-candidate header with role, YOE, and location.
- It adds a semantic-match phrase tuned to the normalized score and real top skills only.
- _career_clause fingerprints the previous row so consecutive current-role snippets never duplicate.
- A Concerns section is driven by Track-1 sub-signals: long notice period, no GitHub, consulting background, short tenure.
- _jd_hits surfaces JD-relevant areas only from skills/text the candidate actually has.
Honeypot avoidance
- There is no separate honeypot detector; resistance is emergent.
- Keyword-stuffed profiles gain little because skills are subordinate and the bi-encoder scores narrative meaning.
- Implausible combinations (consulting-only history, sub-12-month tenure, zero applications) hit the multiplicative penalties and collapse the final score.
Architecture
Screenshots
Limitations
- The demo caps at
MAX_CANDIDATES = 100and runs in memory, skipping the 100K path, artifact caching, and streaming top-N loader. - Demo semantic normalization is relative to the uploaded set, so scores are not comparable across runs.
- Uploads with missing fields fall back to neutral defaults (
avg_response_time → 280.0,notice_period → 90,github → -1), which can flatter or penalize partial profiles. - field_map.py hardcodes EDA-derived ranges (
GITHUB_SCORE_MAX = 96.9,LAST_ACTIVE23–263 days,RESPONSE_TIME2.1–280h,ENDORSEMENTS_MAX = 242) that won't transfer to other distributions. _JD_OFFICE_CITIES = {'pune', 'noida'}is hardcoded because the parser can't separate "office location" from "welcome to apply."interview_completion_rateand standaloneskill_assessment_scoresare excluded for sparsity;current_company_size, India-basedwilling_to_relocate, and certifications carry little weight.- A missing/unparseable
last_active_datescores 0.0 (fully stale, not neutral). consulting_penaltyfalls back to current-company matching when career history is empty.- Consulting detection is substring-based, so a non-consulting firm whose name contains a flagged token can be mismatched.
Future Improvements
- Add a cross-encoder second pass re-scoring only the top-K (~200), slotting between rank_top_n and reasoning.
- Fine-tune
bge-base-en-v1.5(LoRA/QLoRA) on recruiter relevance labels for sharper JD-to-candidate discrimination. - Promote
skill_assessment_scoresto a weighted credibility component once coverage is higher. - Use
company_size,current_industry, and the parsedseniority_level(currently unused in scoring) as additional fit signals. - Learn Track-1 weights and the combination from ground-truth labels (e.g. learning-to-rank) instead of hand-tuning.
- Add explicit honeypot checks: YOE-vs-career-duration consistency, boilerplate-description detection beyond _career_clause, and outlier endorsement/GitHub combinations.